今天给大家分享一个 SQL 窗口函数的速查表,包括窗口函数的语法、窗口函数列表以及相关示例,内容适用于 MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite 等关系型数据库。
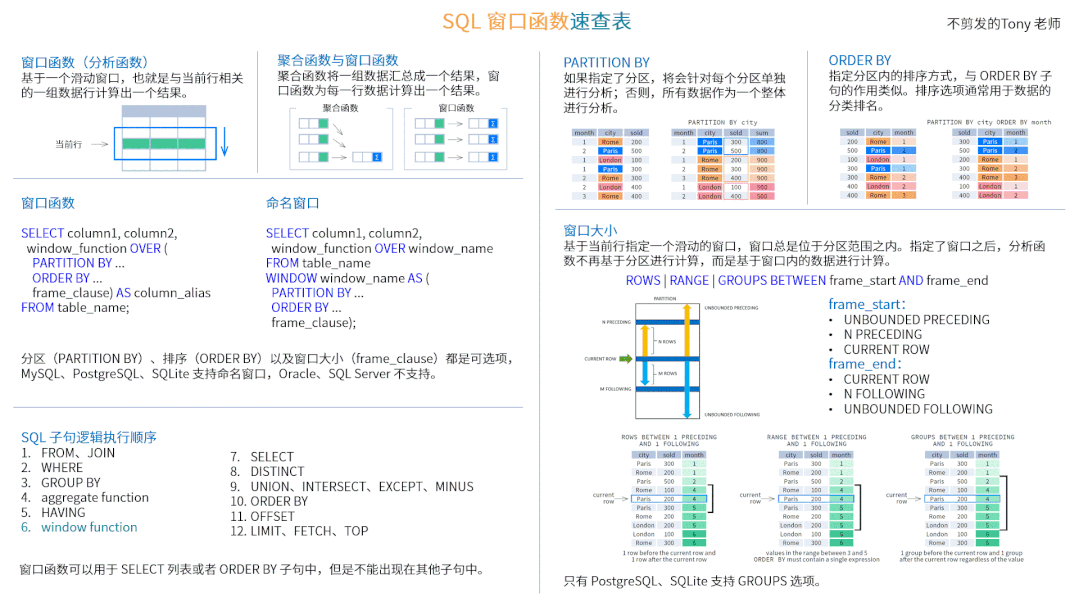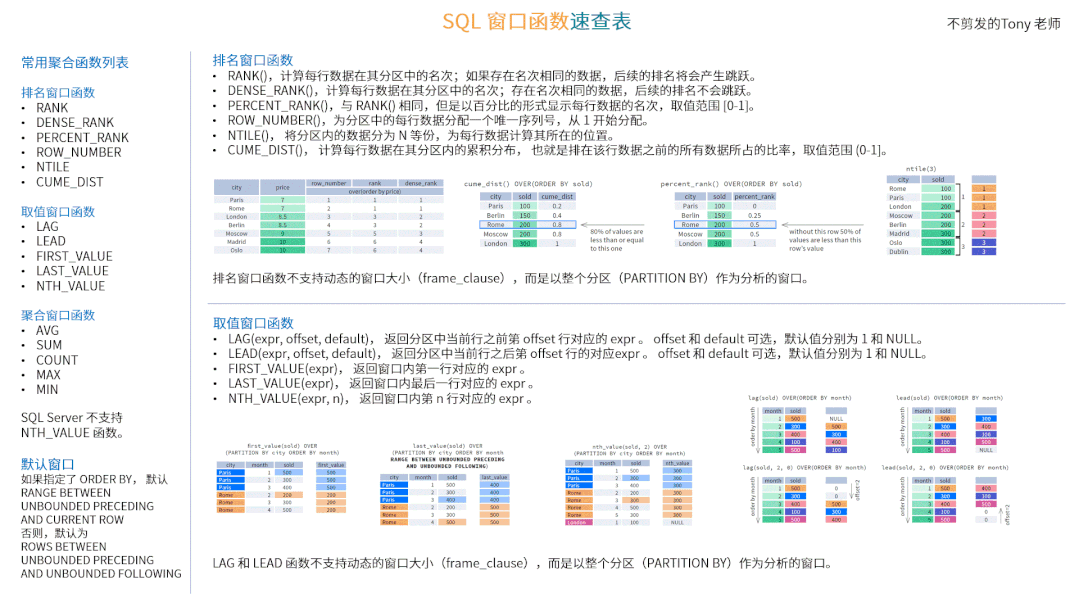
窗口函数概述
窗口函数(Window Function)基于一个滑动窗口,也就是与当前行相关的一组数据行为其计算出一个结果;通常也称为分析函数(Analytic Function)。

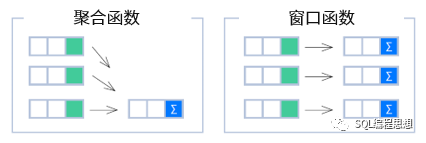
我们知道,聚合函数(Aggregate Function)用于将一组数据汇总成一个结果;而窗口函数则为每一行数据计算出一个结果。它们的区别如下图所示:
窗口函数的语法如下:
SELECT column1, column2,
window_function OVER (
PARTITION BY ...
ORDER BY ...
frame_clause) AS column_alias
FROM table_name;
其中,window_function 是窗口函数的名称;OVER 子句包含三个可选项:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。
以下是一个窗口函数的示例:
SELECT city, month,
sum(sold) OVER (
PARTITION BY city
ORDER BY month
RANGE UNBOUNDED PRECEDING) total
FROM sales;
该查询返回了不同城市,按照月份排序后,累计到每个月份的总销量;OVER 子句中各个选项的作用在下文中进行介绍。
窗口函数还提供了命名窗口的功能:
SELECT column1, column2,
window_function1 OVER window_name
window_function2 OVER window_name
FROM table_name
WINDOW window_name AS (
PARTITION BY ...
ORDER BY ...
frame_clause);
当多个窗口函数的 OVER 子句完全相同,命名窗口可以简化函数的输入。MySQL、PostgreSQL、SQLite 支持命名窗口,Oracle、SQL Server 不支持。
PARTITION BY
OVER 子句中的 PARTITION BY 选项用于定义分区,作用类似于 GROUP BY 分组;如果指定了分区选项,窗口函数将会分别针对每个分区单独进行分析;否则,所有数据作为一个整体进行分析。
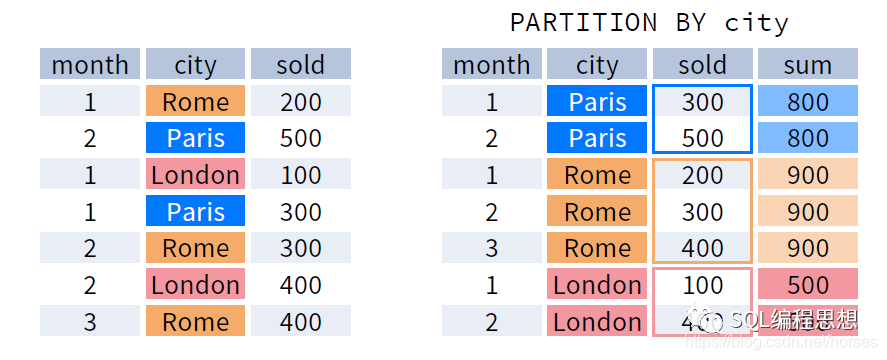
以下查询按照不同 city 统计总销量:
SELECT month, city, sold,
sum(sold) OVER (
PARTITION BY city ) sum
FROM sales;
ORDER BY
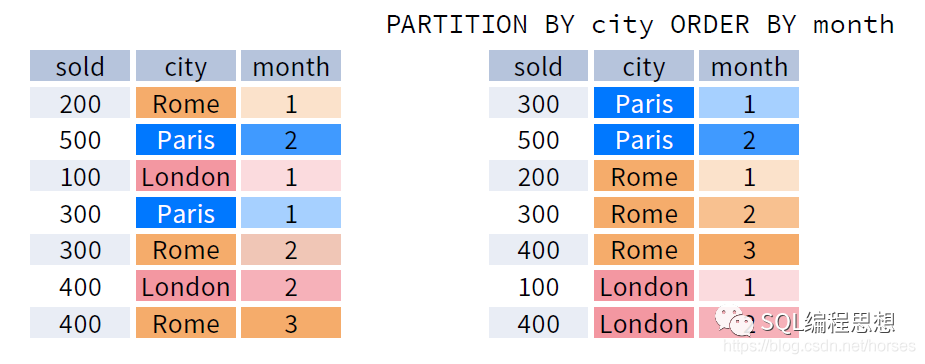
OVER 子句中的 ORDER BY 选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似;排序选项通常用于数据的排名分析。下图演示了按照 city 分区、按照 month 排序之后的数据:
窗口大小
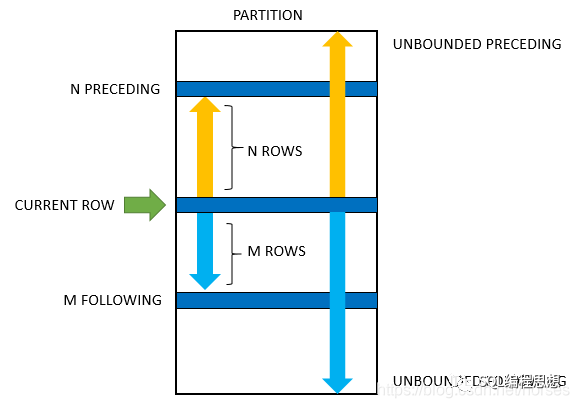
OVER 子句中的 frame_clause 选项用于指定一个滑动的窗口。窗口总是位于分区范围之内,是分区的一个子集。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算。
指定窗口大小的语法如下:
ROWS | RANGE | GROUPS BETWEEN frame_start AND frame_end
其中,ROWS 表示以行为单位计算窗口的偏移量;RANGE 表示以数值(例如 10 天之内)为单位计算窗口的偏移量;GROUPS 以组(ORDER BY 排序相同的数据为一组)为单位计算窗口的偏移量,只有 PostgreSQL、SQLite 支持 GROUPS 选项。
frame_start 用于定义窗口的起始位置,可以指定以下内容之一:
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
以下是窗口选项的一些示例:
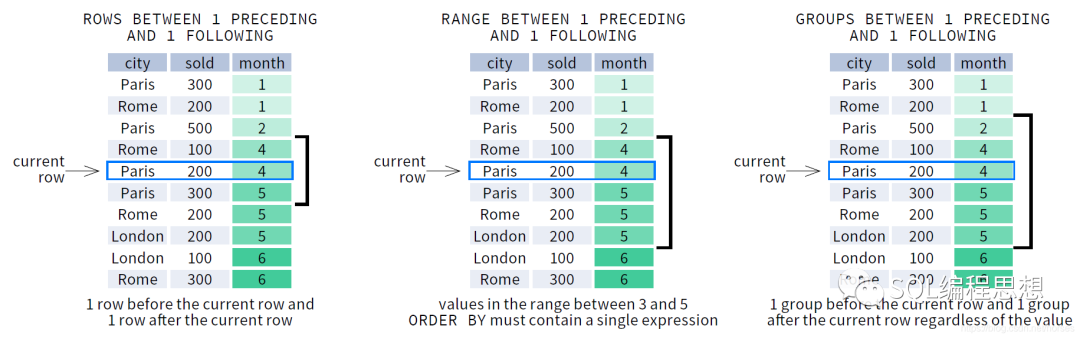
第一个窗口使用 ROWS 选项,包含了前后各 1 行以及当前行;第二个窗口使用 RANGE 选项,包含了当前行的数值减去 1(4-1=3)到当前行的数值加上 1(4+1=5)之间的所有数据;第三个窗口使用 GROUPS 选项,包含了前后各 1 组(ORDER BY 排序相同的数据为一组)和当前行。
如果没有指定窗口大小选项,默认使用的窗口如下:
SQL 子句逻辑执行顺序
窗口函数可以用于 SELECT 列表或者 ORDER BY 子句中,但是不能出现在其他子句中。各种 SQL 子句的逻辑执行顺序如下:
常用窗口函数
排名窗口函数
RANK(),计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
DENSE_RANK(),计算每行数据在其分区中的名次;存在名次相同的数据,后续的排名不会跳跃。
PERCENT_RANK(),与 RANK() 相同,但是以百分比的形式显示每行数据的名次,取值范围 [0-1]。
ROW_NUMBER(),为分区中的每行数据分配一个唯一序列号,从 1 开始分配。
NTILE(), 将分区内的数据分为 N 等份,为每行数据计算其所在的位置。
CUME_DIST(), 计算每行数据在其分区内的累积分布, 也就是排在该行数据之前的所有数据所占的比率,取值范围 (0-1]。
排名窗口函数不支持动态的窗口大小(frame_clause),而是以整个分区(PARTITION BY)作为分析的窗口。
下图演示了 ROW_NUMBER()、RANK() 以及 DENSE_RANK() 函数的效果:
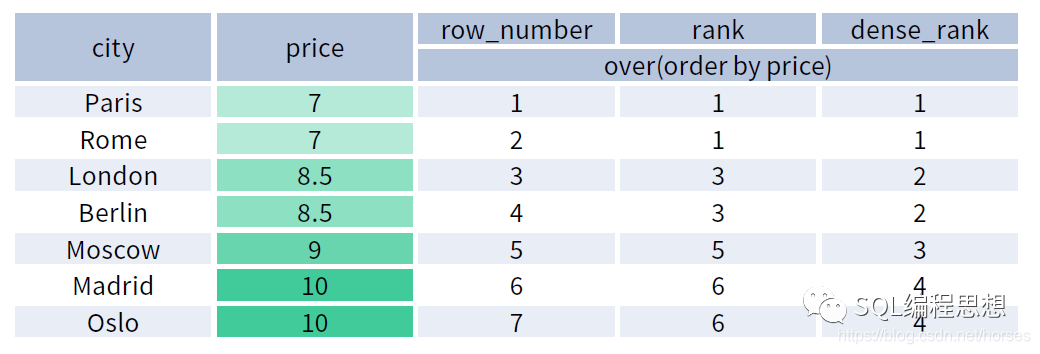
RANK() 和 DENSE_RANK() 函数必须指定 ORDER BY 选项,ROW_NUMBER() 函数可以不指定 ORDER BY 选项。
下图演示了 CUME_DIST() 和 PERCENT_RANK() 函数的效果:

CUME_DIST() 和 PERCENT_RANK() 函数必须指定 ORDER BY 选项。
下图演示了 NTILE() 函数的效果:
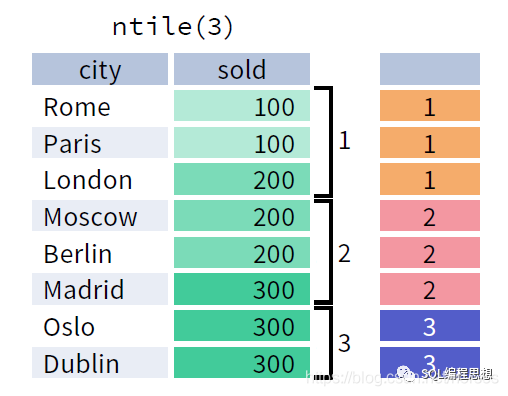
NTILE() 函数必须指定 ORDER BY 选项。
取值窗口函数
LAG(expr, offset, default), 返回分区中当前行之前第 offset 行对应的 expr 。offset 和 default 可选,默认值分别为 1 和 NULL。
LEAD(expr, offset, default), 返回分区中当前行之后第 offset 行的对应expr 。offset 和 default 可选,默认值分别为 1 和 NULL。
FIRST_VALUE(expr), 返回窗口内第一行对应的 expr 。
LAST_VALUE(expr), 返回窗口内最后一行对应的 expr 。
NTH_VALUE(expr, n), 返回窗口内第 n 行对应的 expr 。
LAG 和 LEAD 函数不支持动态的窗口大小(frame_clause),而是以整个分区(PARTITION BY)作为分析的窗口。
下图演示了 LAG(expr, offset, default) 和 LEAD(expr, offset, default) 函数的效果:
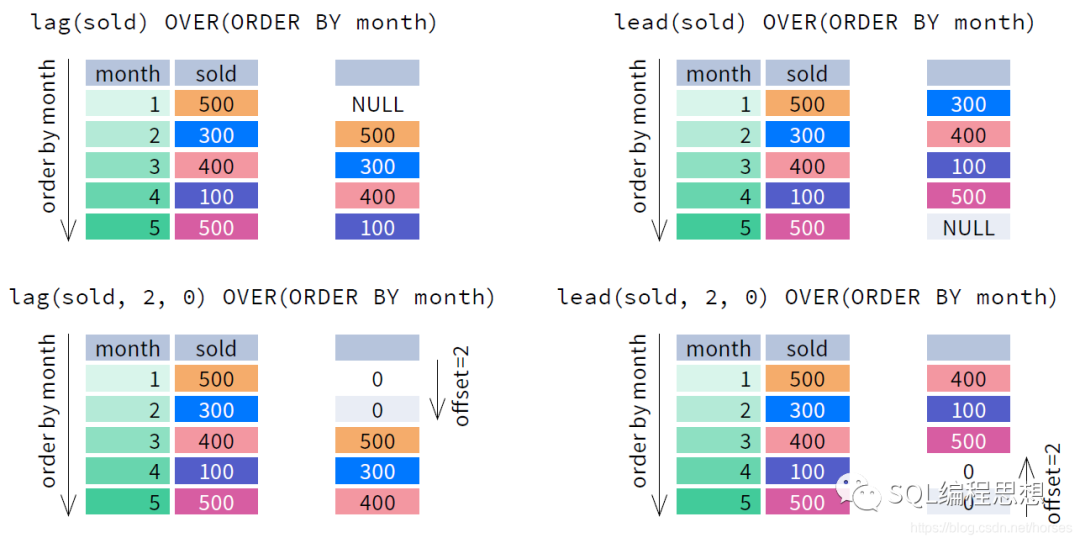
LAG(expr, offset, default) 和 LEAD(expr, offset, default) 函数必须指定 ORDER BY 选项。
下图演示了 FIRST_VALUE(expr) 和 LAST_VALUE(expr) 函数的效果:
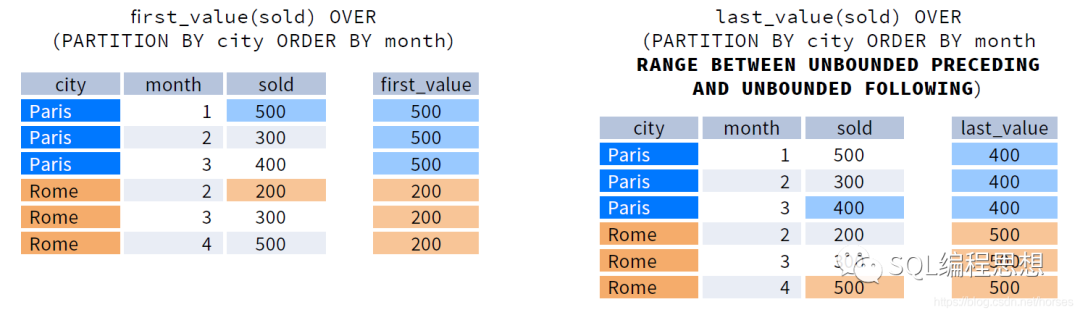
FIRST_VALUE(expr) 和 LAST_VALUE(expr) 函数可以不指定 ORDER BY 选项。
下图演示了 NTH_VALUE(expr, n) 函数的效果:
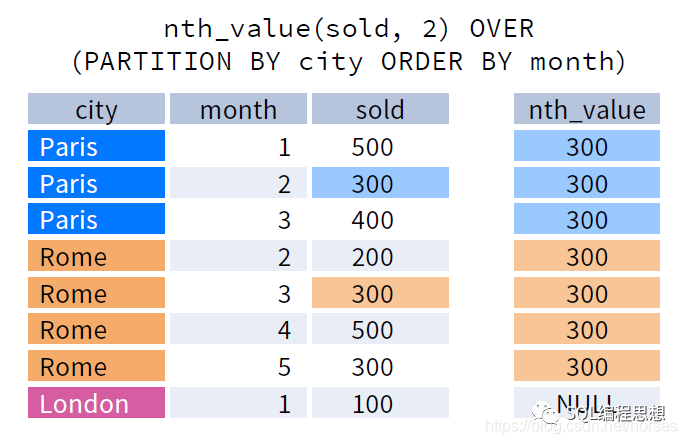
SQL Server 不支持 NTH_VALUE(expr, n) 函数。NTH_VALUE(expr, n) 函数可以不指定 ORDER BY 选项。
聚合窗口函数
AVG(expr),窗口内数据行的平均值;
SUM(expr),窗口内数据行的和值;
COUNT(expr),窗口内数据行的计数;
MAX(expr),窗口内数据行的最大值;
MIN(expr),窗口内数据行的最小值。
聚合函数通常也可以作为窗口函数使用,可以用于计算数据的累计总值和移动平均值。聚合窗口函数可以不指定 ORDER BY 选项。
该文章在 2024/3/15 15:02:11 编辑过






 400 186 1886
400 186 1886


